Morality
(UCLA, BIGAI) An LLM-based agent simulation framework modeling the evolution of morality in prehistoric hunter-gatherer societies
This project was a collaboration with UCLA, Beijing Normal University, and BIGAI. One paper was accepted to ACL 2026 as an Oral presentation: (Zhou et al., 2026).
For more details, visit the project website: MoralAgentSim.github.io.
Why Are We Moral? An LLM-based Agent Simulation Approach to Study Moral Evolution

Overview
The evolution of morality presents a fundamental puzzle: natural selection should favor self-interest, yet humans developed moral systems that promote cooperation and altruism. Traditional approaches—including evolutionary game theory, agent-based models, and anthropological studies—abstract away cognitive processes, leaving open the question of how cognitive factors shape moral evolution.
We introduce an LLM-based agent simulation framework that brings cognitive realism to this question, enabling the manipulation of factors that traditional models cannot represent—such as moral type observability, communication bandwidth, and cognitive constraints—and discovering emergent mechanisms from agent interactions.
Framework
Social-Evol Environment — A simulated prehistoric hunter-gatherer society where:
- Each agent’s HP decays over time and from injury; death occurs when HP reaches 0 or at max lifespan
- Eight action types: collect plants, hunt animals, allocate resources to others, communicate/form coalitions, fight, rob, reproduce, rest
- There is no built-in punishment for antisocial behavior — cooperation emerges from cognition, morality, and ecology alone
MoRE Agent Architecture — Each agent is built on a cognitive architecture where:
- A moral value module conditions how it perceives entities
- Per-entity memory tracks individual interactions
- Agents reason, plan actions, and reflect for consistency
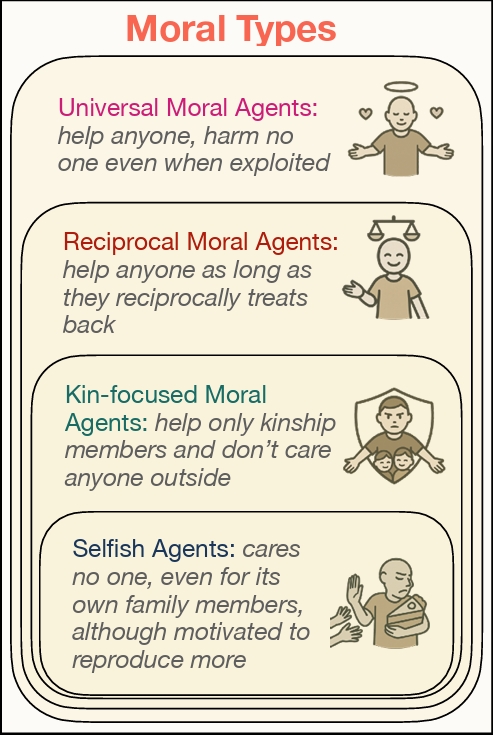
Four Moral Dispositions
Following the “expanding circle” philosophical tradition:
| Type | Radius of Concern | Core Logic |
|---|---|---|
| Selfish | Self only | “Only I matter” |
| Kin-focused | Genetic relatives | “Blood is thicker than water” |
| Reciprocal | Those who reciprocate | “I’ll help those who help me” |
| Universal | Everyone, unconditionally | “Every life has equal worth” |
Key Findings
-
Cooperation Is the Central Driver — Across all experimental settings, cooperative moral types dominate. Universal and reciprocal morality show the most stable outcomes; selfishness never wins in any setting and is eliminated in every run when types are invisible.
-
Cognition as a Central Mediator — Assessing trustworthiness carries a cognitive cost under limited lifespans and misjudgment risk. Universal agents sidestep this cost because they never produce behaviors that could be misread, so their reputation settles quickly. In scarce resource settings, selfish agents preemptively attack one another, reasoning that others pose a life-and-death competitive threat—a self-purging effect not observed in universal agents.
Experimental Settings & Survival Outcomes
| Setting | Description | Top Survivors (fraction of initial N) |
|---|---|---|
| Baseline | Abundant resources, visible types, rich social rounds | Kin 6/8, Universal 4/8, Reciprocal 2/8, Selfish 2/8 |
| Scarce Resource | Reduced resource abundance | Reciprocal 3/4, Universal 2/4, Kin 0/4, Selfish 1/4 |
| High Social Cost | One communication round | Reciprocal 3/4, Universal 2/4, Kin 0/4, Selfish 1/4 |
| Type Invisible | Moral type labels hidden | Universal 4/4, Reciprocal 2/4, Kin 2/4, Selfish 0/4 |
Validation (Four Axes)
- Behavior↔Morality Alignment: 0.89 ± 0.03 diagonal accuracy — GPT-5 evaluator infers moral type from observed behavior
- Cross-Model: Reproducible with Qwen-3.5 and Kimi-K2.5 beyond primary GPT-5-mini
- Architecture Ablation: Full MoRE 0.89 → no modules drops to 0.67; largest single-module drop from removing long-term memory
- Prompt Sensitivity: ≤ 0.03 variation with semantically equivalent rewrites
Broader Significance
The simulations surface established effects from neighboring fields (bounded rationality, costly signalling, altruistic punishment, etc.) without any prior encoding—they emerge bottom-up from agent interactions. The framework generalizes beyond morality: researchers can study cultural backgrounds, religions, political views, or custom social norms using the same engine.
Resources
- Project Website: MoralAgentSim.github.io
- Paper: arXiv:2509.17703
- Code: github.com/MoralAgentSim/social-evol-sim